[Top][All Lists]
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: horrible utf-8 performace in wc
|
From: |
Jim Meyering |
|
Subject: |
Re: horrible utf-8 performace in wc |
|
Date: |
Wed, 07 May 2008 14:51:17 +0200 |
Pádraig Brady <address@hidden> wrote:
> Jan Engelhardt wrote:
>>
>> https://bugzilla.novell.com/show_bug.cgi?id=381873
>>
>> Forwarding this because it is a GNU issue, not specifically a Novell one.
>> I reproduced this myself with the latest coreutils from git
>> (BTW: You might want to repack that repo, "counting objects" during the
>> clone was rather slow in the initial counting.)
>>
>> Could it be a libiconv problem?
>
> Accounting for multibyte characters is what's taking the time:
>
> ~/git/coreutils/src$ time ./wc -m long_lines.txt
> 13357046 long_lines.txt
> real 0m1.860s
>
> ~/git/coreutils/src$ time ./wc -c long_lines.txt
> 13538735 long_lines.txt
> real 0m0.002s
>
> Now that is a _lot_ of extra time. libiconv could probably be
> made more efficient. I've never actually looked at it.
> However wc calls mbrtowc() for each multibyte character.
> It would probably be a lot more efficient to use mbstowcs()
> to convert the whole read buffer.
>
> Note mbstowcs doesn't handle embedded NULs so one would
> need to find these first, and iterate over each substring,
> as I did in my version of uniq previously mentioned.
>
> Also mbstowcs doesn't canonicalize equivalent multibyte sequences,
> and so therefore functions the same in this regard as our
> processing of each wide character separately.
> This could be considered a bug actually- i.e. should -m give
> the number of wide chars, or the number of multibyte chars?
> With the attached patch, `wc -m` gives 23 chars for both these lines.
>
> canonically équivalent
> canonically équivalent
>
> Pádraig.
>
> p.s. I Notice that gnome-terminal still doesn't handle
> combining characters correctly, and my mail client thunderbird
> is putting the accent on the q rather than the e, sigh.
> diff --git a/src/wc.c b/src/wc.c
> index 61ab485..f7f7109 100644
> --- a/src/wc.c
> +++ b/src/wc.c
> @@ -368,6 +368,8 @@ wc (int fd, char const *file_x, struct fstatus *fstatus)
> linepos += width;
> if (iswspace (wide_char))
> goto mb_word_separator;
> + else if (width == 0)
> + chars--; /* don't count combining chars */
> in_word = true;
> }
> break;
[thanks Jan, for forwarding that]
Hi Pádraig,
Thanks for investigating that.
That does look like an improvement. Do you feel like adding
a test case in tests/misc/wc? However, it'll be a little tricky,
because you'll need to include the new test only if there is
sufficient multi-byte support and if you can find a suitable locale to
test with. To set the locale for that one test, put a hashref like
{ENV=>"LC_CTYPE=$locale"} in the test array-ref, where you
detected earlier that $locale is available.
For related examples, run this in your git-cloned coreutils directory:
git grep 'ENV *=>'
Even if you don't have time to write the test, please resend
your patch in "git format-patch --stdout HEAD~1" format so I don't
have to worry about mangling the "á" in your name ;-)
As for rendering, I see odd things, too.
Using emacs (built from git yesterday)
to view these three lines where the 1st and 3rd are identical:
canonically équivalent
canonically équivalent
canonically équivalent
I get results that depend on the font.
(this is with fonts from debian unstable)
Invoking it to use a nice, anti-aliased font,
emacs -fn 'Dejavu Sans Mono-18'
it looks pretty good, but the combining accent could be a
little higher above the "e", rather than touching it.
 djsm-18.jpg
djsm-18.jpg
Description: JPEG image
With any "fixed" variant, the accent is so high above the "e"
that it makes that entire line several pixels higher:
emacs -fn '-*-fixed-*-*-*-*-16-*-*-*-*-*-*-*'
fixed-16.jpg
Description: JPEG image
- Re: horrible utf-8 performace in wc, (continued)
- Re: horrible utf-8 performace in wc, Jim Meyering, 2008/05/07
- Re: horrible utf-8 performace in wc, Bo Borgerson, 2008/05/07
- Re: horrible utf-8 performace in wc, Pádraig Brady, 2008/05/07
- Re: horrible utf-8 performace in wc, Bo Borgerson, 2008/05/07
- Re: horrible utf-8 performace in wc, Pádraig Brady, 2008/05/07
- Re: horrible utf-8 performace in wc, Bo Borgerson, 2008/05/08
- Re: horrible utf-8 performace in wc, Bruno Haible, 2008/05/08
- Re: horrible utf-8 performace in wc, Pádraig Brady, 2008/05/07
- Re: horrible utf-8 performace in wc, Bruno Haible, 2008/05/08
Re: horrible utf-8 performace in wc, Jan Engelhardt, 2008/05/07
Re: horrible utf-8 performace in wc,
Jim Meyering <=
Re: horrible utf-8 performace in wc, Bruno Haible, 2008/05/08
Re: horrible utf-8 performace in wc, Bruno Haible, 2008/05/08
{kind=link}
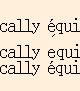{kind=link}