{kind=link}
Description: PNG image
|
| From: | Juergen Sauermann |
| Subject: | Re: [Bug-apl] Performance optimisations: Results |
| Date: | Tue, 01 Apr 2014 18:40:07 +0200 |
| User-agent: | Mozilla/5.0 (X11; Linux i686; rv:17.0) Gecko/20130330 Thunderbird/17.0.5 |
|
Hello,
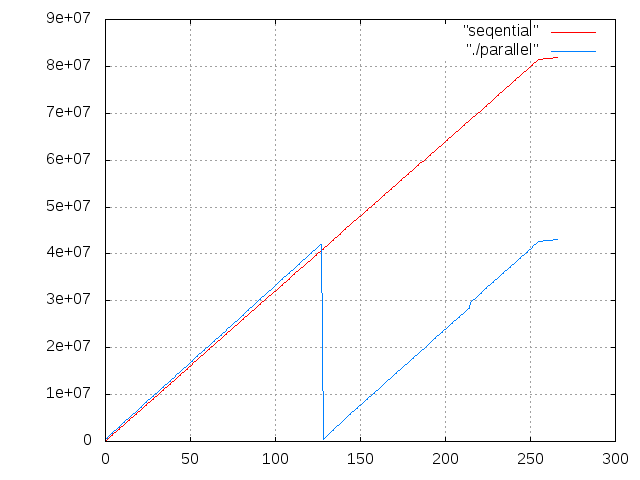
I would like to share some benchmarks on my dual-core (yes, I am a poor guy) machine. The benchmark measures A+A with A←1048576⍴2. The y-axis shows the CPU cycle counter which was recorded every 4096 iterations (so we have 256 samples on the x-axis). The first value was 0 (befor the loop was entered) and the final value was after exiting the loop (in SkalarFunction::eval_skalar_AB(). The way I read these results is that the inner loop for skalar function scales linearly on a 2-core machine. If the total time scales worse then either the sequential part is too big (Amdahls law), or something else is wrong. For example in one of my first tests everything compiled fine but still only one core was used. /// Jürgen On 03/14/2014 05:18 PM, David Lamkins wrote:
|
![]() two-cores.png
two-cores.png
Description: PNG image
![]() seqential
seqential
Description: Text document
![]() parallel
parallel
Description: Text document
| [Prev in Thread] | Current Thread | [Next in Thread] |