we need more mails like yours! Sharing recipes and problems is really heavily appreciated :)
Let me comment on a few things; it's a while back that I worked with the PMT code, though.
Because a PMT vector is pretty much like a python list: It can contain any combination of PMT types, for example:Why does pmt.to_pmt(<python list of complex numbers>) return a vector, but fails when tested under pmt.is_uniform_vector() or any pmt.is_XXXvector() (i.e. c32 for XXX)?
v = pmt.to_pmt(["This is a string", 42, complex(0,-1)])
is perfectly valid, but can't be a uniform vector. Because the input type->output type mapping should be consistent, I consider converting a python list to a PMT vector the right approach.
I personally find "someone decided it was the right thing to do" a bit of a weak argument, though ;). So, here, to at least illustrate how it's done:
pmt.to_pmt is actually a alias[0] for pmt_to_python.py:python_to_pmt(p) [1], which looks like this¹:
def python_to_pmt(p):
for python_type, pmt_check, to_python, from_python in type_mappings:
if python_type is None:
if p == None: return from_python(p)
elif isinstance(p, python_type): return from_python(p)
raise ValueError("can't convert %s type to pmt (%s)"%(type(p),p))
The interesting part is "type_mappings", and that looks like this (just above the python_to_pmt function):
type_mappings = ( #python type, check pmt type, to python, from python
(None, pmt.is_null, lambda x: None, lambda x: PMT_NIL),
...
(complex, pmt.is_complex, pmt.to_complex, pmt.from_complex),
...
(list, pmt.is_vector, pmt_to_vector, pmt_from_vector),
....
(numpy.ndarray, pmt.is_uniform_vector, uvector_to_numpy, numpy_to_uvector),
)
So, a Python object of type "list" is always mapped to a PMT vector.
Also, you might guess what the trick to pmt.to_pmt'able uvectors is: create a numpy.ndarray, and convert it using pmt.to_pmt. numpy has handy conversion functions, as well as it allows you to allocate ndarrays of given type:
#let numpy guess dtype from contents: arr = numpy.array([complex(-1,1), complex(1,-1)]) #or define a ndarray with given shape and type arr = numpy.ndarray(100, dtype=numpy.complex64) p = pmt.to_pmt(arr)If your uvectors migth be larger, I'd recommend pre-allocating the numpy.ndarray, i.e. the second approach.
I'd agree that Tim's gr-eventstream needs quite a bit of understanding on what's happening behind the scenes, but really, it might not be as bad as you feel right now.Anyway, I'll just use pmt.init_c32vector(). I'm trying to create a data payoad for a PDU to send from my custom block to a PDU to tagged stream block such that large packets of samples (tens-of-thousands-of-generated-samples) can be sent out with reliable timing. I first looked into controlling a USRP sink with asynchronous commands, but from what I read, that method has some variability on the order of microseconds (which is still awesome, but I think it might not work well enough). I'm probably going about this all wrong, but it's a learning process, so let me know if there's a glaringly obvious method that I'm overlooking. I first looked into eventstream, as described by the oshearesearch website, but I think that's a bit too far into the deep end for a beginner like myself so far.
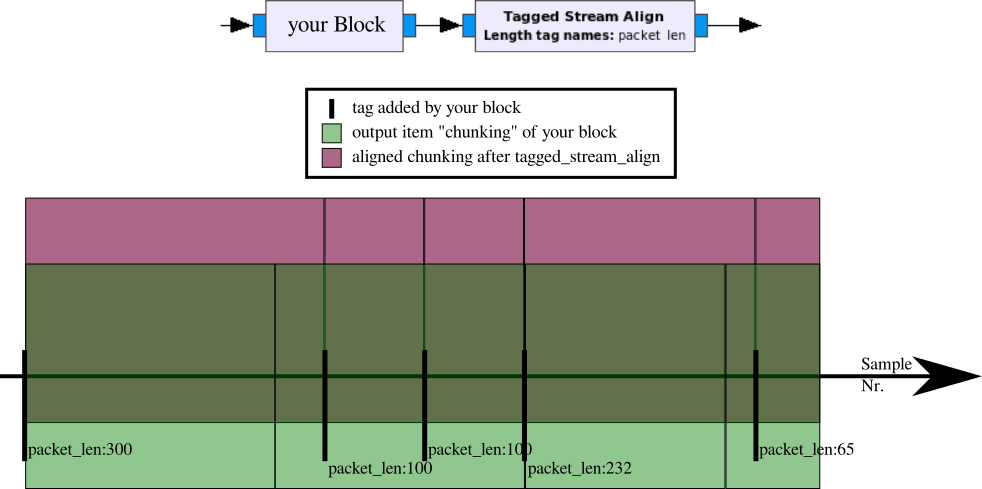
Anyway, tagged stream blocks is probably the solution of choice here; however, I think the elegant solution would be to add tags to your "normal" stream with "length tags" (ie. add a tag to the first item of each "burst" of samples containing the number of samples to come in this burst), and connect your block to the "tagged stream align" block, which sees that its output is so aligned that it's Tagged Stream Block-compatible; I find it non-trivial to explain that concept, but tagged stream blocks are really just "normal" blocks, but for which it's defined that they a) always consume the whole item "chunk" they get, and b) the length of an item chunk is always defined by a value of a tag on the first item (and, c), there's no samples that don't belong to such a chunk); maybe this figure explains its better:
Best regards,
Marcus
¹ Honestly, I just realized that is a relatively inefficient way of implementing this, but I definitely have code in there, and I surely had a reason to do it that way... hm.
[0] "from pmt_to_python import python_to_pmt as to_pmt" in https://github.com/gnuradio/gnuradio/blob/master/gnuradio-runtime/python/pmt/__init__.py#L59
[1] https://github.com/gnuradio/gnuradio/blob/master/gnuradio-runtime/python/pmt/pmt_to_python.py#L130
On 19.12.2015 04:34, Collins, Richard
wrote:
Hello,
I just wanted to share some trouble I had trying to create a pmt uniform c32 vector in python, what I found as the fix, and hope to get some insight as to why things are this way.
Here's an entry from my notes:
THIS CREATES A VECTOR, BUT NOT A UNIFORM OR C32 VECTOR:testv = pmt.to_pmt([complex(1.0), complex(-1.0)]*50)pmt.is_vector(testv) # True
pmt.is_uniform_vector(testv) # Falsepmt.is_c32vector(testv) # False
THIS FAILS:testv1 = pmt.make_c32vector(100, [complex(1.0), complex(-1.0)]*50)
THIS SUCCEEDS, but is a PITA:testv1 = pmt.make_c32vector(100, complex(-1.0))for i in range(pmt.length(testv)):
if i%2 == 0:
pmt.c32vector_set(testv, i, complex(1.0))
THIS IS THE CORRECT WAY TO DO IT:testv2 = pmt.init_c32vector(100, [complex(1.0), complex(-1.0)]*50)
So, it took me quite a while to figure this out. Why does pmt.to_pmt(<python list of complex numbers>) return a vector, but fails when tested under pmt.is_uniform_vector() or any pmt.is_XXXvector() (i.e. c32 for XXX)?
Anyway, I'll just use pmt.init_c32vector(). I'm trying to create a data payoad for a PDU to send from my custom block to a PDU to tagged stream block such that large packets of samples (tens-of-thousands-of-generated-samples) can be sent out with reliable timing. I first looked into controlling a USRP sink with asynchronous commands, but from what I read, that method has some variability on the order of microseconds (which is still awesome, but I think it might not work well enough). I'm probably going about this all wrong, but it's a learning process, so let me know if there's a glaringly obvious method that I'm overlooking. I first looked into eventstream, as described by the oshearesearch website, but I think that's a bit too far into the deep end for a beginner like myself so far.
- Richard
_______________________________________________ Discuss-gnuradio mailing list address@hidden https://lists.gnu.org/mailman/listinfo/discuss-gnuradio