I would like to know what interferer signals occur at different
frequencies in a spectrum. Since I want to get an idea of the average
behaviour of the spectrum, I'd like to look at the spectrum over a long
period of time (hours?).
This would be too much data
to store, so I wrote a custom Python block. It updates power statistics
(specifically the Rayleigh parameter) while the magnitude squared of an
FFT is above a threshold, then writes the power statistics and the time
to a file whenever an element drops below the threshold. This cuts down
the data from tens of MBs to kBs per second.
I got an
overflow (the 0 character) about once every five seconds on the Ettus
310, running at 4MHz and 1024 vector length. To speed up the Python
code, I vectorized the threshold and update code with numpy, and
switched from write_line to numpy's save_txt to save the power
statistics. In testing the new code chewed through 10,000 x 1024 vectors
about thirty times faster than the old code. Feeling very clever, I ran
the new code on the E310, only for it to overflow twice a second.
In
short, my "optimized" Python code seems to run faster in testing, but
overflow more in practice. Could you help me understand why this
happens? I copied some of the relevant code below, and attached a picture of my flowgraph. I'm new to Python and
GNU Radio, so I apologize if my code is particularly un-Pythonic, or if
I've missed something basic. :)
### Old code ###
def write_line(self, bin, theta, n):
now = time.time()
line = str(now) + ',' + str(bin) + ',' + str(theta) + ',' + str(n) + '\n'
self.f.write(line)
def general_work(self, input_items, output_items):
in0 = input_items[0]
for i in range(len(in0[0])):
if in0[0, i] > self.threshold:
self.last_state[0, i] += 1
self.theta[0, i] += in0[0, i] ** 2
elif (self.last_state[0, i] > 0).any():
self.write_line(i, self.theta[0, i], self.last_state[0, i])
self.last_state[0, i] = 0
self.theta[0, i] = 0
will_consume = len(input_items)
self.consume(0, will_consume)
return len(input_items)
### Vectorized code ###
def write_line(self, bin, theta, count):
np.savetxt(self.f, self.fft_num, fmt='%i', newline='\n')
np.savetxt(self.f, np.transpose([bin, theta, count]), fmt='%i %0.7f %i', newline='\n')
# Update fft_num
self.fft_num += 1
def general_work(self, input_items, output_items):
curr_input = input_items[0][0]
# Find entries that just dropped below the threshold
just_dropped = (self.last_state > 0) & (curr_input <= self.threshold)
# Update theta and count
self.last_state[0, curr_input > self.threshold] += 1
self.theta[0, curr_input > self.threshold] += curr_input[curr_input > self.threshold]**2
# Write bins, thetas and counts for this vector
self.write_line(np.nonzero(jus
t_dropped[0])[0], self.theta[just_dropped], self.last_state[just_dropped])
# Reset last_state and theta if below threshold
self.last_state[0, curr_input <= self.threshold] = 0
self.theta[0, curr_input <= self.threshold] = 0
will_consume = len(input_items)
self.consume(0, will_consume)
return len(input_items)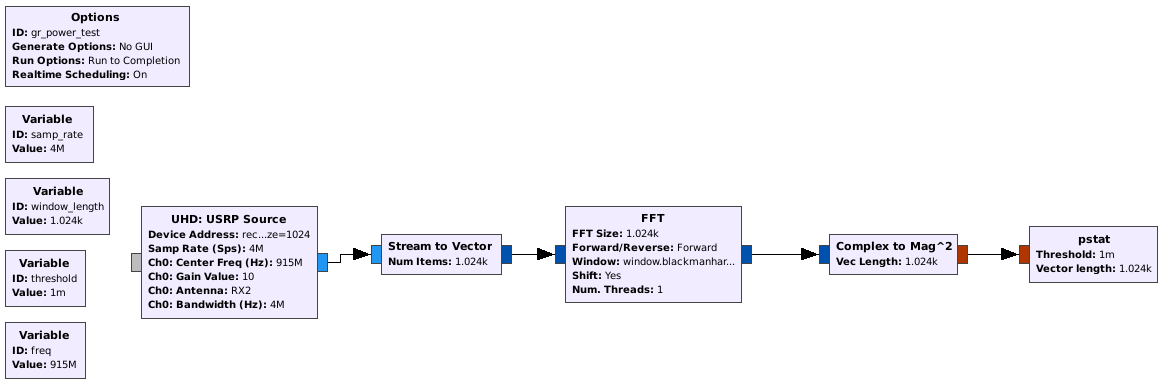{kind=link}