[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
LLM Experiments, Part 2: Structured workflows with org-mode
|
From: |
Andrew Hyatt |
|
Subject: |
LLM Experiments, Part 2: Structured workflows with org-mode |
|
Date: |
Sun, 28 Jan 2024 09:30:51 -0400 |
|
User-agent: |
Gnus/5.13 (Gnus v5.13) |
Hi everyone,
As a follow-on to my last email, I'd like to share another demo, along
with how my thinking has evolved, thanks to the feedback I received, and
further work. Again, feedback and design opinions would be helpful. This
series of emails is trying to work out solutions to tricky design
questions from the emacs community about more complicated LLM
interactions (workflows, as I'm calling them) than have been done
before.
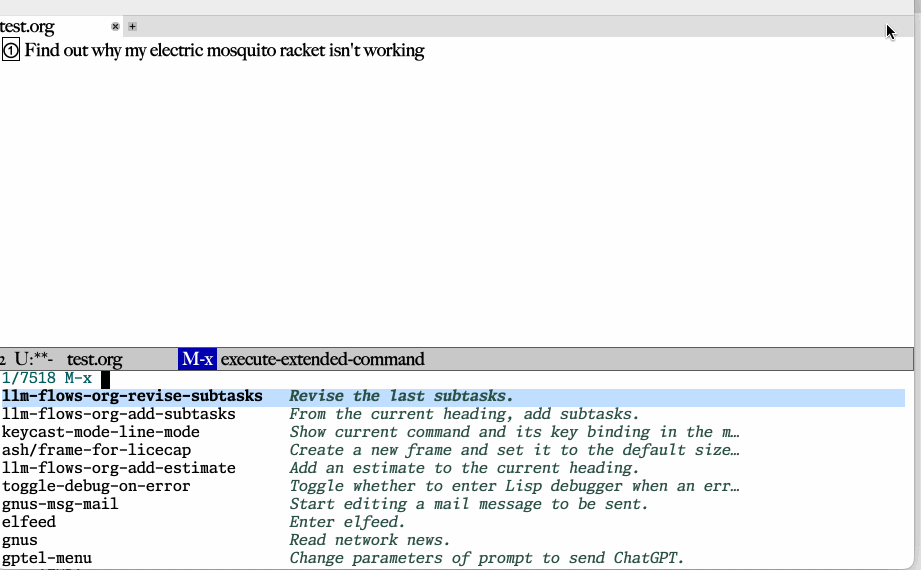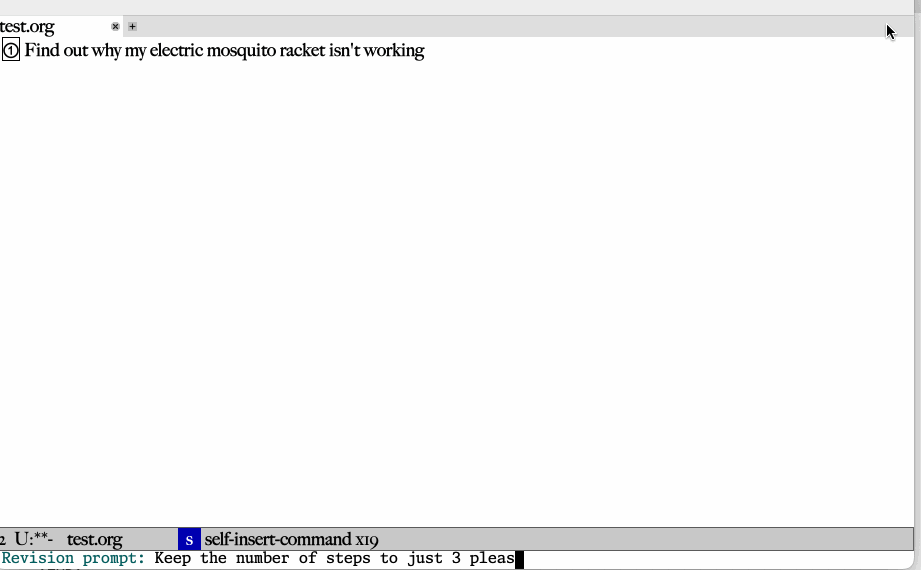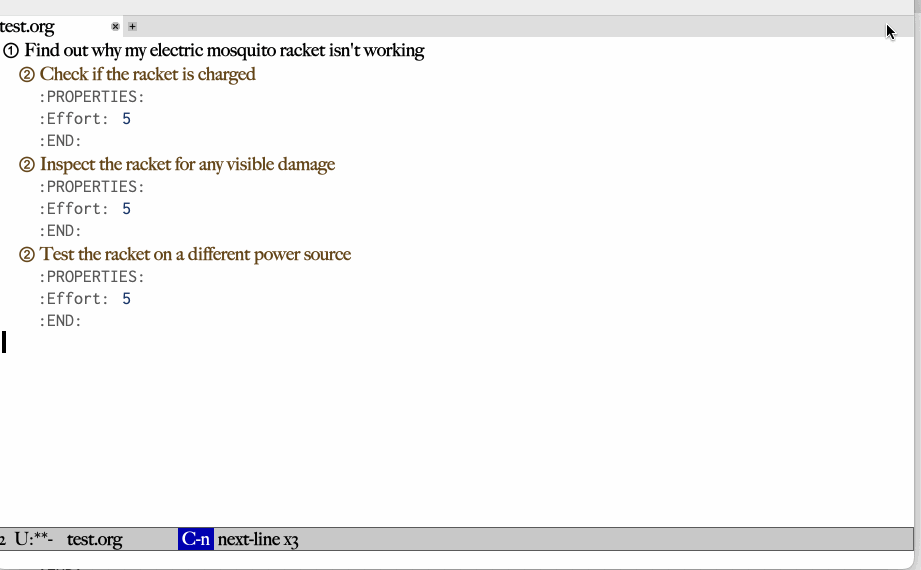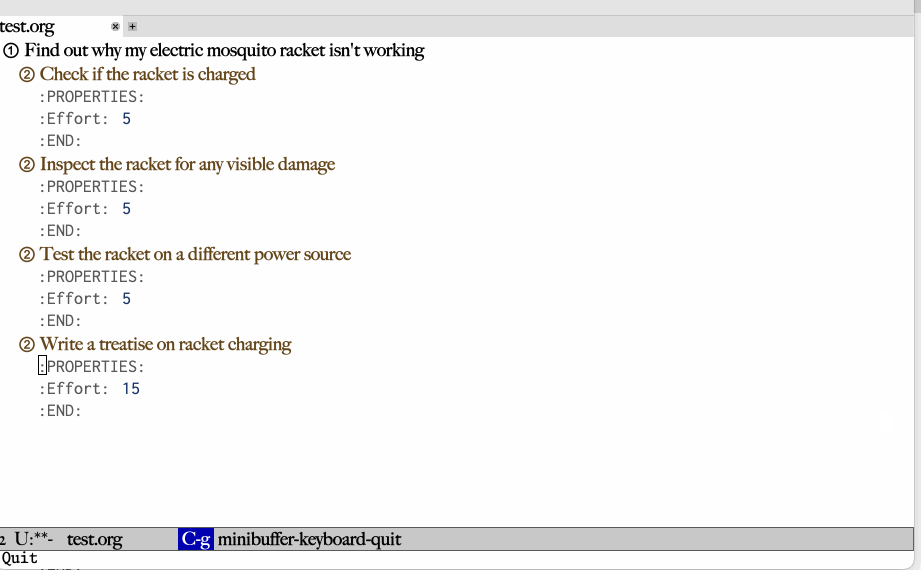
My latest demo is attached, and demonstrates the ability to deal with
structured data. In the demo, I have the LLM take an org headline and
create subtasks it. I then am able to execute another command that
revises that generation, in the same LLM conversation, and regenerate
the subtasks according to the amended conversation. Finally, I
demonstrate a similar feature, having the LLM produce an estimate for
how long (in minutes) a task will take.
One interesting new element here is that to generate org subheadings, we
have to get structured data (a list, basically). That means we have to
implement asking the LLM for JSON, parsing it out, and retrying if it
messes up.
The other interesting part is that there's no previous content here, so
a diff so that the user can check and maybe give feedback to the LLM
didn't make sense. Instead, we have a followup command that will
continue the conversation, undo the previous work, and redo it according
to the new LLM output.
The other new part, not shown, is that now these commands let you use a
prefix arg, in which you can modify the prompt.
The new code in on github, still associated with a branch on the llm
package source. You can see the code here:
https://raw.githubusercontent.com/ahyatt/llm/flows/llm-flows.el
This does allow clients to set up their own user verification, as João
suggested.
The code that uses it for this demo is here:
https://gist.githubusercontent.com/ahyatt/2d5e4fcf8f67d00becc94b51634d8c06/raw/0e2a883f5219ec94df29fbfb80d535889f42fd7c/llm-flows-org.el
And my previous demo is now rewritten like this:
https://gist.githubusercontent.com/ahyatt/63d0302c007223eaf478b84e64bfd2cc/raw/5c5939df364885bf4a4fc243f4a66dab2da41b7d/llm-flows-example.el
I'm going to re-visit the initial questions I asked in my last demo to
see how thinking has evolved.
Question 1: Does the llm-flows.el file really belong in the llm package?
I'm leaning to yes at the moment, since it would add another level of
complexity to the flows code to also have to make how the llm is called.
I'll consider this resolved, but I'm willing to revisit it.
Question 2: What's the best way to write these flows with multiple
stages, in which some stages sometimes need to be repeated? After trying
out simpler solutions and struggling when things out to be my
asynchronous than I thought, I've switched to fsm, and it seemed like a
good fit for the problem, and more flexible than my ad-hoc solutions. I
think I will consider this question closed.
Question 3: How should we deal with context? Since we allow prompt
rewriting, I implemented a small templating system. If there is context,
the user can remove it entirely. Karthik had the opinion that it's good
to give the user more control, and I agree, but it's also a harder
problem that seems like advanced functionality we can leave until later.
Opinions on how much users may want to alter the context would be
helpful.
Question 4: Should the LLM calls be synchronous? I still think they
could be, but with the fsm, they are async. Some things have to be async
anyway, such as waiting for the user to look at an ediff session. This
seems fine, but the client has to make sure to always keep track of the
original buffer and point. A macro can probably help with that. I will
consider this question closed.
Question 5: Should there be a standard set of user behaviors about editing the
prompt? I think so. I will consider this question closed.
Question 6: How do we avoid having a ton of very specific functions for
all the various ways that LLMs can be used? I still don't know. gtpel's
way of doing things probably does make sense for similar text
manipulation commands. ellama's way of having more specific functions
does make things a bit easier and more discoverable, though. One of the
big problems in LLMs is that they are powerful, but it's not always
clear the best way to use them. And with structured commands that do
specific things like in this demo, I don't see a great way to fit those
into a general command. So for this one I'm hoping there may be some way
to strike a balance.
There's two ways I'd like to push this forward before we resolve these
questions and I can finalize a design: I'd like to have an LLM
interaction that doesn't alter a buffer. My next demo will be about
something like setting up tabs or doing some other kind of
emacs-housekeeping task. I also would like to try out more complicated
flows (I don't know what yet), which will be good in understanding how
we can make fsm's state machines easy to create from a standard set of
parts.
Thank you to all who responded previously, it's been very helpful!
| [Prev in Thread] |
Current Thread |
[Next in Thread] |
- LLM Experiments, Part 2: Structured workflows with org-mode,
Andrew Hyatt <=