Hello,
I'm not sure you can assume that a character having code >= 0x80 is part of UTF-8. Beyond what is
called "basic character set" which is globally the ASCII 7bits, there is the "extended
character set" which is implementation defined.
For example, the euro sign € may be part of 8859-15 and perfectly well encoded
on 8bits with 0xA4 see https://en.wikipedia.org/wiki/ISO/IEC_8859-15
Microsoft VC++ has the following flags
/utf-8 set source and execution character set to UTF-8
/validate-charset[-] validate UTF-8 files for only legal characters
That controls how source code is encoded.
gcc (more specifically cpp the C preprocessor) processes source file using
UTF-8 but, as VC++ has a flag to control input-char
-finput-charset=charset
Set the input character set, used for translation from the
character set of the input file to the source character set used by
GCC. If the locale does not specify, or GCC cannot get this
information from the locale, the default is UTF-8. This can be
overridden by either the locale or this command-line option.
Currently the command-line option takes precedence if there's a
conflict. charset can be any encoding supported by the system's
"iconv" library routine.
Now, tcc should be compatible with both. I mean:
- Native Windows tcc port should NOT assume characters are UTF-8 encoded and
-utf-8 flag should change this behavior (+ -finput-charset=xxx for gcc
compatibility)
- Other ports (I mean Linux & alt.) should assume characters are UTF-8 encoded
and -finput-charset=xxx flag should change this behavior (+ -utf-8 for VC++
compatibility)
To summarize, which should add both utf-8 and -finput-charset=xxx support and
set the default behavior based on native port.
Wdyt?
Christian
-----Original Message-----
From: Tinycc-devel [mailto:address@hidden On Behalf Of ???
Sent: mercredi 30 août 2017 09:31
To: address@hidden
Subject: [Tinycc-devel] BUG: wide char in wide string literal handled
incorrectly
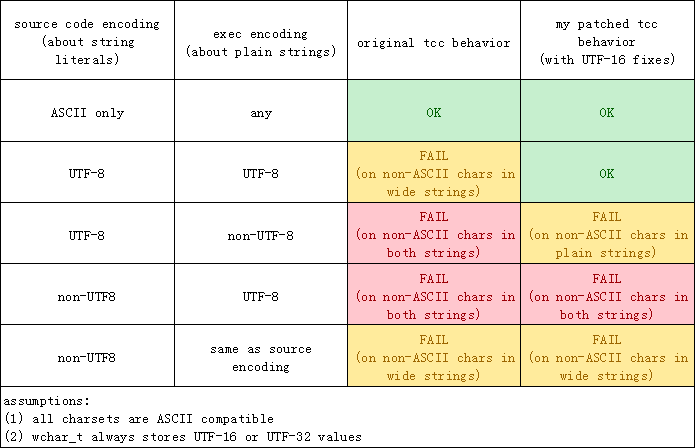
Hello,
I found that when TCC processing wide string literal, it behaves like
directly casting each char in original file to wchar_t and store them in wide
string. This will work for ASCII chars. However, it might not work for real
wide chars. For example:
The Euro-sign (€, U+20AC) stored in UTF-8 is "E2 82 AC". In GCC, this char stored in wide
string will be "000020AC". However, in TCC, this char is stored as 3 wide chars "000000E2
00000082 000000AC".
I provided a patch, a test program and two screenshots that describe this problem,
they are in attachments. I solve this problem by making assumptions that input charset is
UTF-8. Although it's not a perfect solution, it's still better than "directly
casting char to wchar_t". I'm wondering if that is appropriate, so please review the
code carefully.
Thanks
Zhang Boyang
_______________________________________________
Tinycc-devel mailing list
address@hidden
https://lists.nongnu.org/mailman/listinfo/tinycc-devel
{kind=link}