[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: Entering Unicode characters
|
From: |
Oleh Krehel |
|
Subject: |
Re: Entering Unicode characters |
|
Date: |
Tue, 26 Jan 2016 09:38:48 +0100 |
|
User-agent: |
Gnus/5.13 (Gnus v5.13) Emacs/25.0.50 (gnu/linux) |
Marcin Borkowski <address@hidden> writes:
> On 2016-01-25, at 16:37, Richard Stallman <address@hidden> wrote:
>> That is useless in practice, because it requires users to know these
>> long and often obscure names. When I wanted to do this, I was unable
>> to do it with C-x 8. I was totally stumped! All I could do was try
>> to find a file which had the character I wanted.
>>
> Have you heard about autocompletion?
Here is the current capability of `counsel-unicode-char' which is
included in the GNU ELPA swiper package. Note how the regex boundaries
"\b" are used to closely match the letter "a".
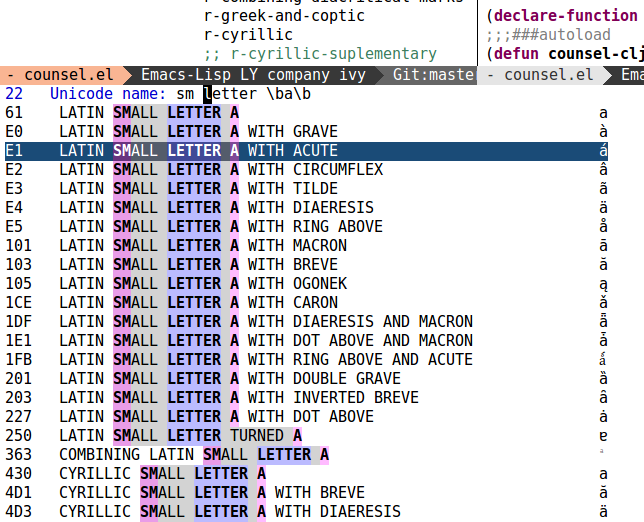
This command is meant to do the same as `insert-char' does.
The only issue is that the built-in `ucs-names' variable, which is
offered for completion, includes around 40000 entries. Maybe there
should be a way for the user to turn off the Unicode ranges she's never
interested in (see the division of ranges in the `nxml-unicode-blocks'
variable). In the included screenshot, I've already disabled some
ranges that aren't interesting for me - my font doesn't have glyphs for
a large portion of these.
Another issue I've found when shortly examining the Unicode table is
that it provides these three categories:
1. Plain letters,
2. Composition characters, like COMBINING GRAVE ACCENT, COMBINING ACUTE
ACCENT etc.,
3 Plain letters pre-combined with the above composition chars.
So maybe the user should decide if she prefers to have 1+2 or 1+3 or
1+2+3, the latter option significantly increasing the number of
completion candidates (by around 2500).
Oleh
- RE: Entering Unicode characters, (continued)
- Re: Entering Unicode characters, Eli Zaretskii, 2016/01/25
- Re: Entering Unicode characters, Vivek Dasmohapatra, 2016/01/25
- Re: Entering Unicode characters, Teemu Likonen, 2016/01/25
- Re: Entering Unicode characters, Eli Zaretskii, 2016/01/25
- Re: Entering Unicode characters, Vivek Dasmohapatra, 2016/01/25
- Re: Entering Unicode characters, Eli Zaretskii, 2016/01/25
- Re: Entering Unicode characters, Marcin Borkowski, 2016/01/25
- RE: Entering Unicode characters, Drew Adams, 2016/01/25
- Re: Entering Unicode characters,
Oleh Krehel <=
- Re: Entering Unicode characters, Tianxiang Xiong, 2016/01/25
- RE: Entering Unicode characters, Drew Adams, 2016/01/25
- Re: Entering Unicode characters, Tianxiang Xiong, 2016/01/25
- Re: Entering Unicode characters, Richard Stallman, 2016/01/26
- Re: Entering Unicode characters, Jean-Christophe Helary, 2016/01/26
- Re: Entering Unicode characters, Eli Zaretskii, 2016/01/26
- Re: Entering Unicode characters, Stefan Monnier, 2016/01/26
- Re: Entering Unicode characters, Jean-Christophe Helary, 2016/01/26
- Re: Entering Unicode characters, Eli Zaretskii, 2016/01/26
- Re: Entering Unicode characters, Jean-Christophe Helary, 2016/01/27